

Grid architektúra
A Grid architektúráját gyakran írják le a "rétegek" szempontjából, mivel mindegyik réteg egy specifikus funkcióért felelős. Általánosságban elmondható, hogy a magasabb rétegek a felhasználóra irányulnak (a zsargonban felhasználó-centrikus), míg az alacsonyabb rétegek inkább a számítógépekre és a hálózatokra fókuszálnak (hardver-centrikus).
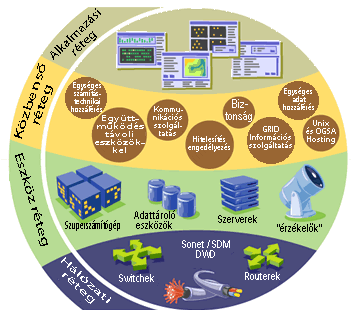
Mindennek az alapja a legalsó réteg, a hálózat, ami biztosítja a kapcsolatot a Grid erőforrásaival. Efelett helyezkedik el az erőforrás réteg, ami a Grid részét képező tényleges erőforrásokból áll. Ezek lehetnek számítógépek, tárolórendszerek, elektronikus adatkatalógusok és még érzékelők is (pl. teleszkópok), melyeket közvetlenül be lehet kötni a hálózatba.
A köztes réteg nyújtja azokat az eszközöket, amelyek lehetőve teszik különböző elemeknek (szerverek, tárolók, hálózatok stb.), hogy az egységesített Grid környezet részét képezhessék. A köztes réteg elképzelhető egy intelligenciaként, amely összehozza a különböző elemeket - így a Grid "agyát" képezi!
A struktúra legmagasabb rétegét képezi az alkalmazás réteg, ez magában foglalja az összes felhasználói alkalmazást (tudományos, mérnöki, üzleti, pénzügyi), valamint a portálokat és fejlesztési eszköztárakat is, melyek az alkalmazásokat támogatják. Ez az a szintje a Gridnek, amit a felhasználók is "látnak" majd.
A legtöbb gyakori Grid architektúrában az alkalmazás réteg egy úgynevezett szolgáltatás réteget is tartalmaz, az általános menedzsment funkciók egyik fajtájaként, mint például egy konkrét felhasználó Grid használatának kvantitatív mérése, amibe a munka számlázása is beletartozik (kereskedelmi modellt feltételezve). Ezen kívül a rendszer általános könyvelést vezet az erőforrások szolgáltatóiról és felhasználóiról - ez fontos tevékenységgé válik, amikor különböző intézetek nagyszámú felhasználóval veszik igénybe ugyanazokat a megosztott erőforrásokat. (A szolgáltatás réteg a felső szinten van, hiszen a felhasználó valójában ezzel lép interakcióba, míg a köztes réteg egy "rejtett" réteg, amivel a felhasználónak nem kell foglalkoznia.)
Vannak egyéb módok is e réteges felépítés bemutatására. A szakértők például a "szövedék" kifejezést kedvelik, a Grid teljes fizikai infrastruktúrájára, beleértve a számítógépeket és a kommunikációs hálózatot. A köztes rétegen belül megkülönböztethetjük az erőforrások és hálózati (összekapcsolhatósági) protokollok rétegét és a kollektív szolgáltatások magasabb rétegét.
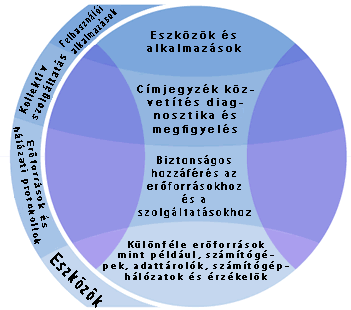
Az erőforrások és az összekapcsoló protokollok kezelik az összes "grid specifikus" hálózati tranzakciót a különböző számítógépek és a Grid egyéb erőforrásai között. Ne feledjük, hogy a Grid által használt hálózat maga az Internet, ugyanezt a hálózatot használja a Web és még számos egyéb szolgáltatás, mint amilyen az e-mail is. Számtalan tranzakció folyik bármelyik pillanatban az Interneten, és a Gridhez tartozó aktív számítógépeknek fel kell ismerniük azokat az üzeneteket, melyekkel foglalkozniuk kell, és ki kell szűrniük a többit. Ezt a feladatot a kommunikációs protokollokkal végzik, melyek lehetővé teszik az erőforrások közötti információcserét, engedélyezik az adatcserét, valamint a hitelesítési protokollokkal, melyek biztonságos mechanizmusokat nyújtanak mind a felhasználók, mind az erőforrások identitásának ellenőrzéséhez.
A kollektív szolgáltatások is protokollokon alapulnak: információs protokollok, melyek megszerzik a felépítésre és az erőforrások állapotára vonatkozó információkat, és a menedzsment protokollok, melyek egy egységes módon "megbeszélik" az erőforrásokhoz való hozzáféréseket. Ezek a szolgáltatások a következőket tartalmazzák:
- az elérhető erőforrások folyamatosan frissített nyilvántartása
- az erőforrások adásvétele (hasonlít a tőzsdei ügynökösködéshez, tárgyalásokat vezet azok között , akik erőforrásokat "venni" szándékoznak, és azokkal, akik "eladják" őket)
- a Griden felmerülő problémák megfigyelése és diagnosztizálása
- a kulcs adatok másolása, így több másolat lesz elérhető különböző helyeken a könnyebb felhasználás érdekében
- tagsági/házirend szolgáltatások nyújtása annak számontartásáért, hogy ki, mit és mikor tehet a Griden.
Az összes sémában a legfelsőbb szint az alkalmazás réteg. Az alkalmazások az összes alattuk levő rétegre építenek a Grid szabályszerű futása érdekében. Vegyünk egy megbízható konkrét példát; gondoljuk át egy felhasználói alkalmazás működését, melynek számos független fájl adatát kell elemeznie. Ennek érdekében:
- megszerzi a hitelesítéshez szükséges információkat a fájlok megnyitásához (erőforrások és kapcsolódási protokollok)
- lekérdezi az információs rendszert és a másolat katalógust az adott kérdésben használható fájlok és másolatok Griden való megtalálásához, ugyanúgy ahogy az elemzésre alkalmas számítási erőforrások megleléséhez is (kollektív szolgáltatások)
- felterjeszti a kéréseit a "szövedékre" - ezt alkotják a megfelelő számítógépek, tárolórendszerek és hálózatok - az adatkivonatoláshoz, a számítások elvégzéséhez és az eredmények megszerzéséhez (erőforrások és hálózati protokollok)
- megfigyeli a különböző számítások és adatátvitelek folyamatait, értesíti a felhasználót az elemzés elkészültével, valamint felismeri és kezeli az esetleges hibákat (kollektív szolgáltatások).
Tisztán látszik, hogy mindezek elvégzéséhez a felhasználó által használt önálló PC-re megírt alkalmazást adaptálni kell a helyes szolgáltatások és protokollok bevonhatósága érdekében. Mint ahogy az alkalmazások "webesítése" történik - amikor a felhasználó adaptálja önállóan működő alkalmazását azért, hogy futtathasson egy web-böngészőt - úgy fogja a Grid is megkívánni felhasználóitól, hogy tegyenek némi erőfeszítést alkalmazásuk "gridesítése" érdekében. Így aztán nincs ingyenebéd, még a Griden sem!
Azonban ha már egyszer megtörtént a gridesítés, emberek ezrei használhatják immár ugyanazt az alkalmazást, problémamentesen futtatva a Griden (nos, nyilván, ahogy a legtöbb szoftver esetében, mindig előfordulhat itt-ott néhány bug), a köztes réteget használva a szövedék változó körülményeihez való adaptációknál.